Inside Llm Inference Gpus Kv Cache And Token Generation Information Center
Get comprehensive updates, key reports, and detailed insights compiled from verified editorial sources.
About of Inside Llm Inference Gpus Kv Cache And Token Generation

Try Voice Writer - speak your thoughts and let AI handle the grammar: The In this deep dive, we'll explain how every modern Large Language Model, from LLaMA to GPT-4, uses the Most devs are using LLMs daily but don't have a clue about some of the fundamentals. Understanding Same prompt. Same model. The first call costs $1.00. The second costs $0.05. Same words — 20× cheaper. The reason isn't a ... Welcome to the ultimate PyTorch + LLMs series! In this first episode, we're going deep into how PyTorch powers Large Language ... Open-source LLMs are great for conversational applications, but they can be difficult to scale in production and deliver latency ...
About the seminar: Speaker: Junchen Jiang (UChicago & LMCache) Title: Next-Gen Long-Context ... This is a single lecture from a course. If you you like the material and want more context (e.g., the lectures that came before), check ...
Core Information

Explore the main sources for Inside Llm Inference Gpus Kv Cache And Token Generation.
History

Stay updated on Inside Llm Inference Gpus Kv Cache And Token Generation's newest achievements.
Featured Video Reports & Highlights
Below is a handpicked selection of video coverage, expert reports, and highlights regarding Inside Llm Inference Gpus Kv Cache And Token Generation from verified contributors.

Inside LLM Inference: GPUs, KV Cache, and Token Generation
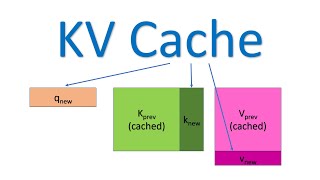
The KV Cache: Memory Usage in Transformers

KV Cache: The Trick That Makes LLMs Faster

KV Cache in LLM Inference - Complete Technical Deep Dive
Expert Insights
Data is compiled from public records and verified media reports.
Last Updated: May 22, 2026
Conclusion

For 2026, Inside Llm Inference Gpus Kv Cache And Token Generation remains one of the most searched-for profiles. Check back for the newest reports.
Disclaimer:



















![KV Caching: Speeding up LLM Inference [Lecture]](https://i0.wp.com/ytimg.googleusercontent.com/vi/_quDGLpNols/mqdefault.jpg?resize=320,180)
