Transformer Encoder Architecture Attention Is All You Need Information Center
Get comprehensive updates, key reports, and detailed insights compiled from verified editorial sources.
Overview on Transformer Encoder Architecture Attention Is All You Need

For more information about Stanford's online Artificial Intelligence programs visit: This lecture covers: 1. Abstract: The dominant sequence transduction models are based on complex recurrent or ... Build better full-stack authentication and user management with Clerk: -- The professional version of this graduate course, XCS224N Natural Language Processing with Deep Learning, runs June ... Welcome to Lecture 4 of the course "Large Language Models" by Prof. Mitesh M.Khapra. Full Course: ... Lex Fridman Podcast full episode: Please support this podcast by checking out ...
00:00 标题和作者03:21 摘要08:11 结论10:05 导言14:35 相关工作16:34 模型1:12:49 实验1:21:46 讨论.
Important Facts

Explore the main sources for Transformer Encoder Architecture Attention Is All You Need.
Latest News

Stay updated on Transformer Encoder Architecture Attention Is All You Need's latest milestones.
Featured Video Reports & Highlights
Below is a handpicked selection of video coverage, expert reports, and highlights regarding Transformer Encoder Architecture Attention Is All You Need from verified contributors.

Attention in transformers, step-by-step | Deep Learning Chapter 6
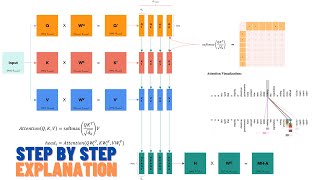
Attention is all you need (Transformer) - Model explanation (including math), Inference and Training

Stanford CS231N | Spring 2025 | Lecture 8: Attention and Transformers

Pytorch Transformers from Scratch (Attention is all you need)
Deep Dive
Data is compiled from public records and verified media reports.
Last Updated: May 22, 2026
Future Outlook

For 2026, Transformer Encoder Architecture Attention Is All You Need remains one of the most talked-about profiles. Check back for the newest reports.
Disclaimer:


















